Phase 2 of Project Omega at TNA (The National Archives) commenced at the end of January 2021, and our first goal was to perform a large export of their Catalogue Records from their previous system, ILDB (Microsoft SQL Server), into our new pan-archival RDF data model. I previously discussed the tooling that we were building to enable such ETL (Extract Transform Load) processes.
Whilst improving the ETL pipeline I experienced some interesting problems when trying to parse and process what I believed to be already computed dates from ILDB. These values that looked like dates suitable for computation were expressed as serial numeric values, for example in that scheme the 17th March 2021, would be expressed as 20210317.
I later found out that even before the year 2000, The National Archives had already encountered this problem. Difficulties that arose previously from attempting to store historical dates as computable dates, gave rise to the decision at that time to store them as text and to convert regnal years (e.g. 3 Eliz I) into serial numeric values rather than computable date values.
The existing data in the ILDB system should adhere to TNA-CS13 (
The National Archives - Cataloguing Standards, June 2013) specification, which itself is an extension of ISAD(G) (General International Standard Archival Description).
Covering Dates
The date Data Elements that I was trying to process are known in TNA-CS13 as the Covering Dates, and are described as:
Identifies and records the date(s) of creation of the records being described.
As a non-archivist, I personally find the term Covering Dates non-intuitive! The first time I encountered it some years ago I incorrectly assumed that it was the period of time discussed in the records, as opposed to the creation date(s) of the records themselves.
The expert archivist however exactly understands the concept of Covering Dates, and I am told that:
An archival catalogue describes records/documents not historical events. The catalogue is agnostic to historical events and so is the archivist. All intrinsic metadata in the catalogue refers to the record. There may be extrinsic metadata providing contextual information (generally added later as a result of enrichment) but the dates refer to the records.
Further explanation of how to complete the Covering Dates is also provided:
"Give the covering dates of the creation of the records within the unit of description as a single calendar date or range of dates as appropriate."
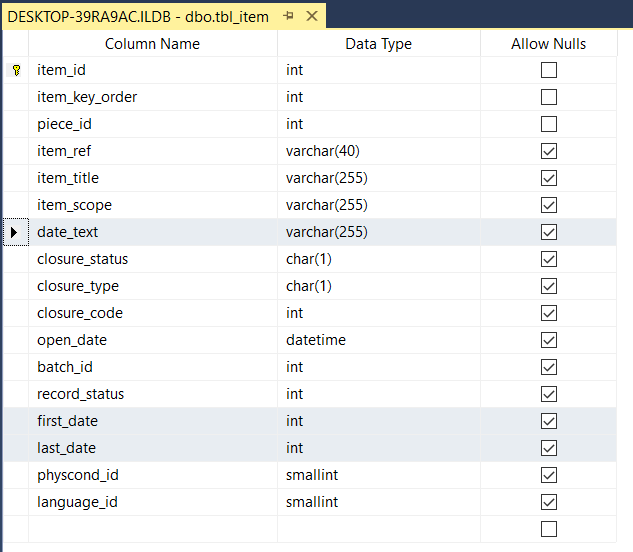
Within the database behind ILDB, the Covering Dates are stored using 3 fields:
date_textThis is a textual description of the dates as they appear in the document or file (or the metadata for a born-digital folder file or folder). It outlines the date or range of dates when the document or file was created or accumulated.first_dateThis is the earliest creation date of any record within the unit of description. It is stored as a serial numeric value of the formyyyyMMdd.last_dateIf the unit of description encompasses more than one record and those records have different creating dates, then this is the latest creation date of any record within that unit. If there is only a single record, or all creation dates are the same within the unit, then this duplicates thefirst_date. It is stored as a serial numeric value of the formyyyyMMdd.
The system attempts to infer the first_date and last_date fields from the date_text as explained in TNA-CS13, however ultimately the archivist can override this behaviour manually:
Dates must be entered in a particular format because the covering date format automatically generates numeric start and end dates in the catalogue in order to enable date searching.
Data for archival catalogues was often generated through the conversion of paper lists into digital form. In the days before the internet, archivists typed the calendar year before the month and the day as this helped readers to rule out or identify relevant information faster. If you are familiar with ISO 8601 style dates, then this will be somewhat familiar to you already.
Some example Covering Dates:
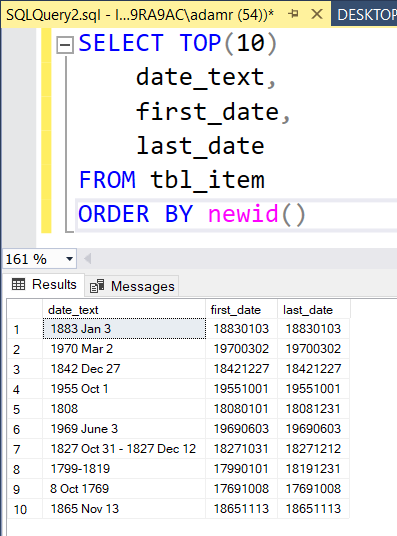
Problems Processing Covering Dates
For our RDF data model, we wanted to express the Covering Dates using W3C OWL-Time. We had decided upon using either an Instant for a single covering date where the first and last dates are the same, or a ProperInterval for a covering date where the first and last dates differ.
During our ETL process we have a step which parses the numeric first_date and last_date fields into Java Date objects, and later a subsequent step that adds these to our RDF Model as xsd:date literals.
During execution of the ETL which was in total processing ~8.2 million records at item level, we would occasionally see a perplexing error related to first_date:
covering_date_start String(9) : couldn't convert string [15821011] to a date using format [yyyyMMdd] on offset location 8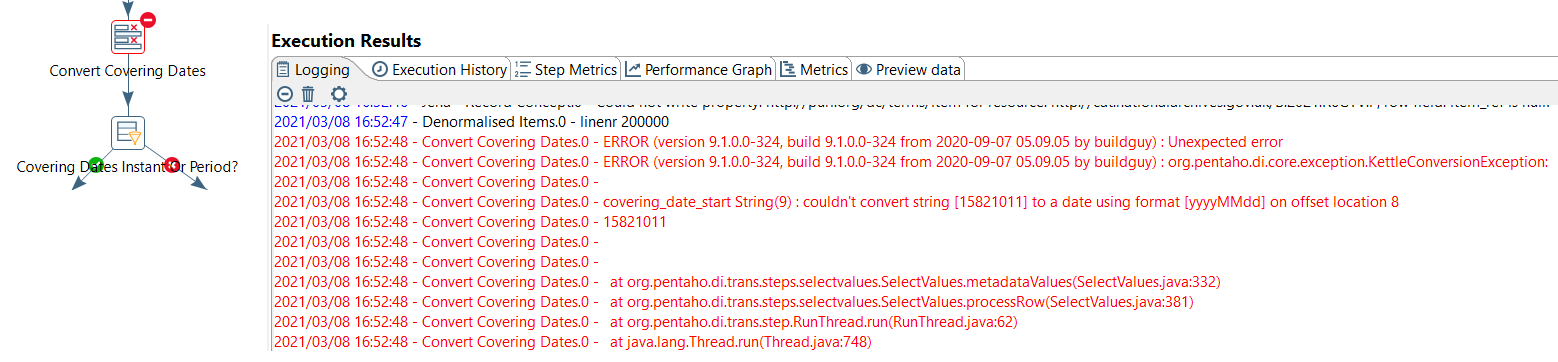
To the uninitiated (i.e. my past self), the string 15821011 looks like it should be parsable using the pattern yyyyMMdd; I can see the year is 1582, the month is October, and the day of the month is the 11th. So what's wrong with this?
Reproducing the Issue
As Pentaho is written in Java, my first thought was to try and reproduce the issue in a couple of lines of Java code, so that I can either rule in or out an issue with Pentaho. So I wrote the following idiomatic Java code:
import java.text.ParseException;
import java.text.ParsePosition;
import java.text.SimpleDateFormat;
public class DateTest {
public static void main(final String args[]) throws ParseException {
final String input = "15821011";
final SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
final ParsePosition pp = new ParsePosition(0);
sdf.parse(input, pp);
if (pp.getErrorIndex() >= 0) {
// error occurred
throw new ParseException("Unable to parse: '" + input + "'", pp.getErrorIndex());
}
}
}The above code did not throw a ParseException, thus meaning that it was able to parse the date just fine. This made me suspect that there must be some difference between the above and how Pentaho is parsing the date itself.
To confirm this, I started Pentaho Spoon with a Java debugging agent configured for remote access, connected to it from IntelliJ IDEA and set some break-points in the Select Values step class (org.pentaho.di.trans.steps.selectvalues.SelectValues) that is used for parsing the date into a Java Date object. Through running the ETL and stepping through the executing code using the Java Debugger I was able to ascertain, that by default the step was calling SimpleDateFormat#setLenient(boolean) with the argument false before parsing the date.
Whether lenient parsing is enabled by default for SimpleDateFormat depends on the Calendar that backs it. This in itself depends on your JDK Platform and likely your locale. On my en_GB.UTF-8 system with OpenJDK 8, the lenient setting is inherited from java.util.Calendar where it is enabled by default.
Modifying our reproducible Java code to disable lenient parsing yields:
import java.text.ParseException;
import java.text.ParsePosition;
import java.text.SimpleDateFormat;
public class DateTest {
public static void main(final String args[]) throws ParseException {
final String input = "15821011";
final SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
sdf.setLenient(false); // disable lenient parsing mode
final ParsePosition pp = new ParsePosition(0);
sdf.parse(input, pp);
if (pp.getErrorIndex() >= 0) {
// error occurred
throw new ParseException("Unable to parse: '" + input + "'", pp.getErrorIndex());
}
}
}The above modified code does indeed now throw a ParseException as a result of trying to parse the date 15821011. So far so good, we have isolated and reproduced the issue!
It's all about the Calendar!
So, 15821011 looks like a valid date... so why does it not parse when lenient parsing is disabled?
Our first hint is from examining the result of sdf.parse (as a String) when lenient parsing is enabled. The result is:
Thu Oct 21 00:00:00 CET 1582Interesting! I was expecting the 11th October 1582, but we are told that we have the 21st October 1582.
I previously had a basic understanding that there was a Julian Calendar and that this pre-dated the creation and use of the Gregorian Calendar, and that the switch-over happened in October 1582. That switch-over happened such that, Thursday 4th October 1582 (Julian Calendar) was followed by Friday 15th October 1582 (Gregorian Calendar). I can only imagine that this must have confused a few people who woke up on that Friday morning ;-)
As the calendar switched from Julian to Gregorian in October 1582 we can see that according to the Julian-Gregorian hybrid calendar (which is what Java uses by default on my platform) there was no 11th October 1582, and therefore 15821011 is not a valid date (for that Calendar).
So what's up with lenient parsing? Basically SimpleDateFormat makes a best effort attempt to interpret the supplied date. As 11th October 1582 falls in the period between the Julian-Gregorian switch-over, Java adds 10 days (the difference at that time between the calendars), to yield the 21st October 1582 in the Gregorian Calendar. However, that's not really what we want! We want non-lenient parsing as we may have other dates in the source data that are actually incorrect and we don't want them slipping through undetected.
...and if that was the end of it, it wouldn't be too bad as we could just correct an invalid date in the source data. However, that date is perfectly valid... keep reading!
Julian-Gregorian Switch-Over Wasn't Universal!
Simply put, whilst most of Roman Catholic Europe switched from Julian to Gregorian calendars in October 1582, other countries followed later. The countries now making up the UK and Ireland are important in this story because this date comes from The Catalogue of The National Archives, and they didn't in fact switch-over until almost 200 years later - 14th September 1752.
When given a date, I think you actually have to know two things to be able to parse it, 1) the date itself, and 2) to which Calendar the date is in reference to. Our date 11th October 1582 (15821011) is perfectly valid in the UK at that time (according to the Julian Calendar), as the UK had not yet switched over to the Gregorian calendar.
When parsing 15821011 in Java, we need to instruct Java to use the correct Calendar configuration. Initially I (incorrectly) assumed that Java would know the switch-over dates on a per-country basis and adjust its Julian-Gregorian calendar appropriately, as such I tried setting both the Locale and Time Zone to UK:
import java.text.ParseException;
import java.text.ParsePosition;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.GregorianCalendar;
import java.util.Locale;
import java.util.TimeZone;
public class DateTest {
public static void main(final String args[]) throws ParseException {
final String input = "15821011";
final Locale ukLocale = Locale.UK;
final SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd", ukLocale);
final TimeZone ukTimeZone = TimeZone.getTimeZone("Europe/London");
final GregorianCalendar ukCalendar = new GregorianCalendar(ukTimeZone, ukLocale);
sdf.setCalendar(ukCalendar);
sdf.setLenient(false); // disable lenient parsing mode
final ParsePosition pp = new ParsePosition(0);
final Date result = sdf.parse(input, pp);
if (pp.getErrorIndex() >= 0) {
// error occurred
throw new ParseException("Unable to parse: '" + input + "'", pp.getErrorIndex());
}
System.out.println("Result: " + result.toString());
}
}Unfortunately, as mentioned above, my assumption that Java would configure the Julian-Gregorian switch-over date automatically once it knew the Locale and Time Zone was incorrect; the above code still throws a ParseException.
Once you know where to look, this is documented and expected behaviour. Java's GregorianCalendar class documentation states:
GregorianCalendaris a hybrid calendar that supports both the Julian and Gregorian calendar systems with the support of a single discontinuity, which corresponds by default to the Gregorian date when the Gregorian calendar was instituted (October 15, 1582 in some countries, later in others). The cutover date may be changed by the caller by callingsetGregorianChange().
Historically, in those countries which adopted the Gregorian calendar first, October 4, 1582 (Julian) was thus followed by October 15, 1582 (Gregorian). This calendar models this correctly. Before the Gregorian cutover, GregorianCalendar implements the Julian calendar.Therefore, to construct a calendar that respects the UK Julian-Gregorian calendar switch-over we can call setGregorianChange with an argument of 14th September 1752. For example:
import java.text.ParseException;
import java.text.ParsePosition;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import java.util.GregorianCalendar;
import java.util.Locale;
import java.util.TimeZone;
public class DateTest {
public static void main(final String args[]) throws ParseException {
final String input = "15821011";
final Locale locale = Locale.UK;
final TimeZone timeZone = TimeZone.getTimeZone("Europe/London");
// setup a UK Julian-Gregorian Calendar with the correct switch-over date for the UK
final GregorianCalendar ukJulianGregorianCalendar = new GregorianCalendar(timeZone, locale);
final GregorianCalendar ukGregorianCalendarCutoverDate = (GregorianCalendar) ukJulianGregorianCalendar.clone();
ukGregorianCalendarCutoverDate.set(1752, Calendar.September, 14);
ukJulianGregorianCalendar.setGregorianChange(ukGregorianCalendarCutoverDate.getTime());
final SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd", locale);
sdf.setCalendar(ukJulianGregorianCalendar);
sdf.setLenient(false); // disable lenient parsing mode
final ParsePosition pp = new ParsePosition( 0 );
final Date result = sdf.parse(input, pp);
if ( pp.getErrorIndex() >= 0 ) {
// error occurred
throw new ParseException( input, pp.getErrorIndex());
}
System.out.println("parsed='" + result.toString() + "'");
System.out.println("serialized='" + sdf.format(result) + "'");
}
}
NOTE: In the above code the call to Calendar#set(int, int, int) takes arguments for a year, a month, and a day, but... the month argument is zero-based and not one-based! So for September you must enter 8 and not 9! Alternatively you can use the constants from the Calendar API, e.g.: set(1752, Calendar.September, 14). This small difference confused me for some time :-(
The most important thing to note in the code above, is that we have still explicitly disabled lenient parsing, but because we have correctly set the UK Julian-Gregorian switch-over date, we can now parse our date 11th October 1582 (15821011) without any errors. The result of the above code is:
parsed='Thu Oct 21 01:00:00 CET 1582'
serialized='15821011'Now you might be thinking... Hang-on one hot-moment, the parsed line still says "21st October 2021"!
Indeed it does! However, that is correct because as explained in Java's GregorianCalendar class documentation:
GregorianCalendarimplements proleptic Gregorian and Julian calendars. That is, dates are computed by extrapolating the current rules indefinitely far backward and forward in time. As a result,GregorianCalendarmay be used for all years to generate meaningful and consistent results.
The important term above is "proleptic", and I will leave that for the reader to look up. I am simplifying but you can expect the Java Date class to always represent dates internally according to the Gregorian Calendar. That's not a problem because we can convert forward and backward as needed between Calendar representations. This is demonstrated by the serialized output line in the results above.
Now that our Calendar is correctly configured (for the UK) in Java we have no problem parsing our Covering Dates. Unfortunately I have been unable to find any options for configuring this in Pentaho for our ETL, and as such we have 2 options:
- As Pentaho is Open Source, we could improve Pentaho's Select Value step to offer suitable configuration.
- Create a custom Pentaho Plugin step which handles such date parsing.
I may cover such topics in a future post, but we won't consider Pentaho any further today.
What about that RDF?
As briefly mention earlier we want to output our Covering Dates into our RDF using a W3C OWL-Time format. We need to incorporate the 3 fields: date_text, first_date, and the optional last_date. The first_date and last_date fields are now valid Java Date objects according to our calendar (as discussed above), whilst the date_text remains a string value.
An example, of a Covering Date indicating a single point in time for a unit of description, may have the date_text with a value of 1859 Aug 30, and only a first_date with a value of 18590830. This can be expressed in our RDF model for Project Omega as:
omg:created [
a time:Instant ;
dct:description "1859 Aug 30" ;
time:inXSDDate "1859-08-30Z"^^xsd:date
] .Another example, of a Covering Date indicating a period of time for a unit of description, may have the date_text with a value of 11 Oct 1582 - 29 Nov 1582, the first_date with a value of 15821011, and last_date with a value of 15821129. This can be expressed in our RDF model for Project Omega as:
omg:created [
a time:ProperInterval ;
dct:description "11 Oct 1582 - 29 Nov 1582" ;
time:hasBeginning [
a time:Instant ;
time:inXSDDate "1582-10-21Z"^^xsd:date
] ;
time:hasEnd [
a time:Instant ;
time:inXSDDate "1582-12-09Z"^^xsd:date
]
] .Now, if you have been paying close attention so far, you will have noticed that the literal values of the time:inXSDDate properties don't look like the first_date and last_date values!
However, if I told you that these dates in RDF are stored according to the xsd:date (W3C XML Schema Date) data-type, and that that specifies a proleptic Gregorian Calendar, then perhaps you might have an "Ah ha!" moment.
If not, then let me explain that the dates in the RDF are the Gregorian equivalent of the Julian dates that were provided as input. No information has been lost as you can convert back and forward between these with relative ease.
Finally, The Archivist vs. The Software Engineer
The Digital Humanities require a fine and pragmatic balance between Human and Technical factors.
Software Engineering - Technical Factors
In the example of storing these Covering Dates in RDF the Software Engineer has proposed storing them as xsd:date typed values. The software Engineer recalling that TNA-CS13 states:
the covering date format automatically generates numeric start and end dates in the catalogue in order to enable date searching.
believes that the date_text is the important property from an archival descriptive perspective, and that the first_date and last_date are really just present to enable the access function of searching records by dates. The Software Engineer also understands by assumption that the first_date and last_date should be in synchronisation with the date_text and therefore be a faithful representation of that period.
For the software engineer, how the first_date and last_date are stored is a technical consideration that centers around arguments of accuracy, performant indexing, and range searches over dates. The Software Engineer believes that dates for dates to be processed consistently in isolation, they must be expressed according to a Calendar and Time Zone. In effect 3 facts are required to process a date, the date itself, the calendar for which the date is expressed, and any Time Zone information for how that date is recorded.
Ultimately, should there be a presentation requirement, the Software Engineer knows that they can convert the first_date and last_date and present/search it in any format requested by the user. The Software Engineer is confident that no information has been lost or destroyed.
Archival - Preservation Factors
The archivist is concerned that at present the first_date and last_date are recorded as simple sequential numbers. The archivist understands the context of the record, and is happy to glance at the serial date and interpret it within its historical context. The archivist believes that all 3 properties (first_date, last_date, and date_text) are equally important from a records keeping perspective and should be preserved as is.
The archivist worries that the raw expression of an xsd:date e.g. 1859-08-30Z may be harder to interpret that the previous serial format: 18590830; worse yet, dates that were written for the Julian Calendar (as that was the Calendar in use at that date) e.g. 15821129 might now be expressed as 1582-12-09Z for the Gregorian Calendar. Without careful explanation to the user, the new Gregorian form of the Julian date is confusing, and use of the original serial format of date perhaps makes more sense.
In Conclusion - Human and Technical Together
Ultimately, all of these dates regardless of their formatting for expression relative to a particular calendar are stored as electro-magnetic 1s and 0s on a disk. The current serial formatted first and last dates stored in ILDB are SQL Integers laid down inside a complex proprietary MS SQL Server database format, that likely few could hope to decipher!
Ignoring for the moment the field of Digital Preservation, we can have the best of both worlds. The Software Engineer can design correct and performant software, which accurately records the dates, and that the archivists and the users can be presented and allowed to search those dates in whichever format is most desirable. Such presentation could include displaying the calendar or adjusting the display dates to the historically relevant calendar for the record.
This Omega Catalogue system is designed to be an online system, for the purposes of Digital Preservation, one could imagine preserving frequent exports of our RDF data as perhaps Turtle or similar (UTF-8 encoded text). As a Software Engineer and potential Digital Archeologist I would argue that (given pre-knowledge of the spec), it is much easier to interpret and process 1582-12-09Z over 15821129, as the first form can only be according to the Gregorian Calendar (as per the W3C specifications for the XML Schema Date Type) and also indicates the time-zone (the Z character denotes UTC). I therefore have everything I need within the date string itself. I don't need to research further into the history of Julian to Gregorian Calendar switch-overs, which I would otherwise have to do with the second form!