;tldr: Jena Plugins for Pentaho Kettle (GitHub), and Demo of building a SQL to RDF Workflow (YouTube).
Background
At the end of 2019 TNA (The National Archives) launched a small Proof-of-Concept project called Project OMEGA. The goal of Project OMEGA was to investigate and prototype a potential replacement for their Catalogue. Initially the scope of the project was limited to PROCat and ILDB, the GUI and database respectively, that forms their existing Catalogue system for physical (e.g. paper) records.
After much research into TNAs business of cataloguing, and at our suggestion, the project has been expanded. The goal of the project is now to build a new singular "Pan-Archival Catalogue" system, which will replace several existing systems, and be able to describe all types of records held by TNA, i.e. physical, born-digital, and digital surrogates.
One of the obvious complexities for a Pan-Archival Catalogue is bringing together data about records from multiple sources, each of which has a different logical model. We opted to first identify a new suitable data model for TNAs future Pan-Archival Catalogue, after evaluating the major models in use, and the latest research for archival records modelling, we settled upon a Graph based model. The Graph based model allows us to describe complex relationships between records, and to easily add new facts and relationships to the graph in future as TNAs knowledge and interpretation of its records is enriched.
In a previous post entitled - "Pentaho KETTLE and SQL Server", I explained that we were using Pentaho Kettle to work with our initial data from ILDB which is a SQL Server database. Having chosen a Graph based data model, and specifically RDF (Resource Description Framework), we needed to have our data transformation workflows in Kettle produce RDF output for us. Unfortunately, out-of-the box Kettle doesn't include any workflow steps for producing RDF, and we could not find any 3rd-party plugins to do this. So we built and Open Sourced our own...
Integrating Kettle and Jena
Fortunately we were able to develop custom workflow steps to generate RDF in Java for Pentaho Kettle's plugin API. For the heavy RDF lifting, our custom workflow steps make use of Apache Jena, which is a Java framework for building Semantic Web and Linked Data applications. Our workflow steps provide the UI dialogs for configuration in Kettle, and act as the glue between Kettle and Jena by mapping row fields from Kettle to RDF Resources and Properties in Jena.
We developed two custom workflow steps:
- Create Jena Model
For each input row provided by Kettle, a Jena Model is created and stored as a target field in the output row. The step allows the user to configure a mapping of fields from the input row to RDF Resources and Properties in the Jena Model of the output row. - Serialize Jena Model
This step is designed to receive input rows from Kettle which contain a Jena Model as one of their fields (created via a Create Jena Model step). The step allows the user to configure a file path and RDF serialization type, for a file that will be serialized to disk from the Jena Model.
For anyone else who wants to create RDF with Pentaho Kettle, TNA have kindly agreed to release these custom workflow step plugins as Open Source under the MIT license. If you are interested, you can read more about TNA's Open Source licensing policy. The plugins were developed in Java 8 and tested with Pentaho Kettle 8.3.0.9-719 and Apache Jena 3.14.0. You can find them on their GitHub: https://github.com/nationalarchives/kettle-jena-plugins

Configuring the Create Jena Model step
The Create Jena Model step is concerned with mapping fields from the input row to an RDF Resource and Properties in the output row. The step's configuration dialog is shown below.

- Target Field Name
This is the name of the field in the output row which will hold the Jena Model. You can call this anything you want, e.g.my_jena_model. - Remove Selected Fields?
When thus is selected, then any fields added in the Fields to RDF Properties table, will no longer be available in the output row. - Namespace Prefix / Namespace URI
This table holds the namespace mappings. You must add entries in here for any prefixes which you use in the Resource rdf:type field, or Fields to RDF Properties table. - Resource rdf:type
This is the name of the RDF class that your resource instantiates. - Resource URI (field)
This is the field from the input row which contains the URI of your resource. - Fields to RDF Properties
This table maps input row fields to RDF Properties. If you leave the RDF Property type empty, thenxsd:Stringis assumed. Rather than properties, you can also map to other resources by setting the RDF Resource type toResourceand making sure that your field contains a URI or QName.
Configuring the Serialize Jena Model step
The Serialize Jena Model step is concerned with serializing a previously created Jena Model which is present in a field of the input row. Typically a Serialize Jena Model step follows a Create Jena Model step. The step's configuration dialog is shown below.
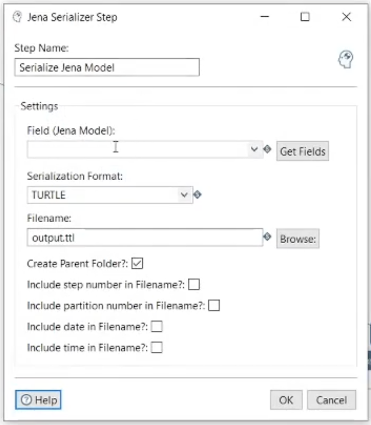
- Field (Jena Model)
This is the name of the field in the input row which contains the Jena Model. This should be the same as the Target Field Name from the corresponding Create Jena Model step. - Serialization Format
The format of the RDF file that you wish to create. e.g.RDF/XML,RDF/XML-Abbrev,N3,Turtle, orN-Tripples. - Filename
This is the path and name of the file on disk that you wish to create. - Create Parent Folder
When checked, the parent folder of the output file will be created if it does not already exist. - Include step number in Filename
When checked, the Kettle step number will be appended into the output filename. This can help to uniquely identify the output file in complex workflows. - Include partition number in Filename
When checked, the Kettle partition number will be appended into the output filename. This can help to uniquely identify the output file in complex workflows. - Include date in Filename
When checked, the date will be appended into the output filename. This can help to uniquely identify the output file in complex workflows. - Include time in Filename
When checked, the step number will be appended into the output filename. This can help to uniquely identify the output file in complex workflows.
Demo of building a SQL to RDF Workflow
We have also produced a simple screencast which demonstrates using our plugins to create RDF from a SQL database.