I have recently completed work on a new BLOB (Binary Large Object) store for eXist-db which along with a couple of other changes replaces its previous Binary Document storage facility. The initial goal that I set out to solve was that of duplicate documents, I will explain the evolution of the design of my new BLOB Store and some of its more interesting properties.
tl;dr This article provides comprehensive details of the new BLOB Store design, if you just want to read the highlights and download the software, you can skip to the Summary.
History
First, let's set the scene... A rich Git history is a wonderful thing! We have gone to great trouble in the eXist-db project to ensure its integrity, consciously preserving our entire SCM history; Through our initial migration from SourceForge CVS to SVN, and then later with our migration to Git on GitHub.
Such a history allows me to easily delve into the past, for example, I can show you evidence that eXist-db first supported storing XML documents, and that non-XML (or Binary) documents were added later by Wolfgang Meier in November 2003. Like XML documents, the Document Object for a Binary Document was stored into the Collections Table (collections.dbx file), whilst its content, or BLOB, was stored into pages in the DOM (Document Object Model) File (dom.dbx) alongside the nodes of XML documents.
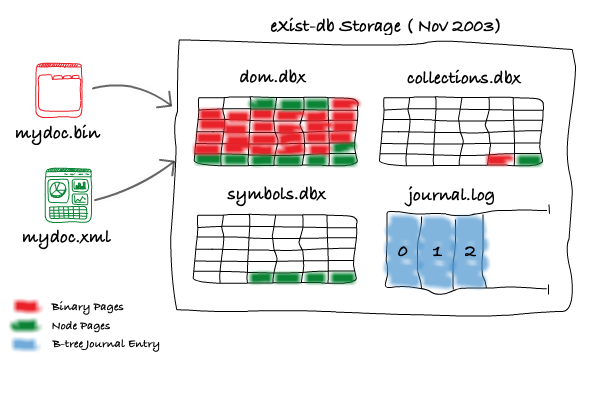
Unfortunately, this meant that adding a few large Binary Documents to the database could rapidly increase the storage and memory requirements of the DOM B-tree, consequently making searches through the tree when accessing the nodes of XML documents much slower.
Alex Milowski recognised this in October 2008 and supplied a series of patches which continued to keep the Document Object for a Binary Document in the database's Collections Table, but crucially, moved the content BLOB of the binary document out of the database's DOM B-tree and into a file on the filesystem. This was no small feat as further write-ahead-logging facilities also had to be added at that time to ensure crash safe consistency between the B-tree holding the Document Object and the content BLOB of the document on the filesystem.

Apart from some recent improvements (which we will discuss shortly) that were made to correct and improve the write-ahead-facilities for the crash recovery of Binary Documents, Alex's changes have held up well over the years. Thank You Alex :-)
Terminology
A quick explanation of the terminology used here on in:
-
Collections Table - Holds details of the Collections and Documents present in the database. This is a B-tree paged storage file, named
collections.dbx. -
Document Object - Just the description of a Document in the database, not its content, although it may provide methods to reach its content. The Document Object is kept in the Collections Table.
-
XML Document - A type of Document Object which represents an XML Document. The content of an XML Document is kept in the DOM File.
-
Binary Document - A type of Document Object which represents a non-XML Document.
-
DOM File - A B-tree paged storage file, named
dom.dbx, which holds the nodes of XML documents. -
BLOB file - A file on the filesystem containing the content of a Binary Document.
New BLOB Store Design - Round 1, UUIDs
Right, now back to 2018... it turns out that data storage requirements have exploded! As we all now know, people want to store all of the things, all of the time.
One such company that uses eXist-db is Jorsek LLC, who wanted to be able to store vast quantities of binary documents alongside their XML documents in their easyDITA CCMS (Component Content Management System). Jorsek kindly provided the sponsorship and impetus for eXist-db's new BLOB store, by setting me the challenge of being able to copy documents in eXist-db without the need to make a copy of the document's content. The initial focus was to be on Binary Documents with the idea of adding support for XML documents in the future.
In more general terms, the idea is that you can store (or copy) the same Binary Document within eXist-db as many times as you like, but that its content should only need to be stored once. A new copy of the content only needs to be stored if the document is modified.
Even after Alex's improvements in 2008, there was still a 1-to-1 mapping in eXist-db between the Binary Document stored in the CollectionsTable and the document's content. For XML Documents, these are the Document Node's children stored in the DOM B-tree. For Binary Documents, this is the binary content stored in a BLOB file on the filesystem in the $DATA_DIR/fs/db folder.
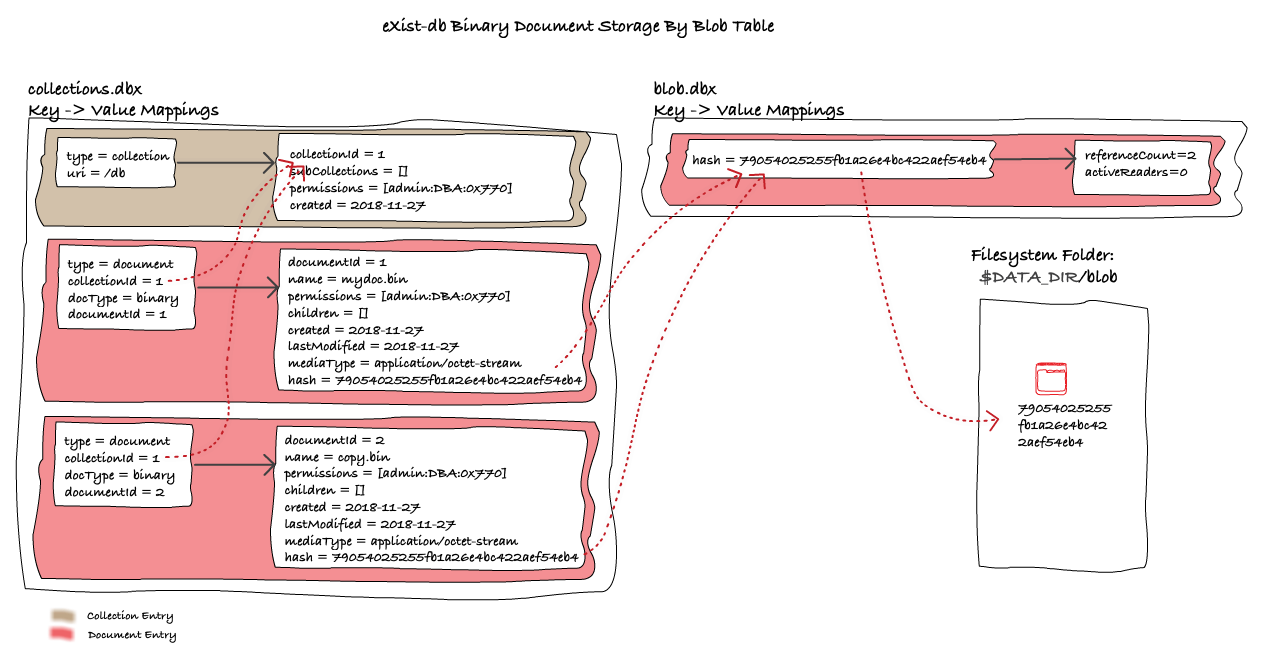
That means that for Binary Documents, the Collection hierarchy of the database is mirrored to the filesystem folder $DATA_DIR/fs/db, under which there is one filesystem folder for each Collection and one BLOB file on the filesystem for each Binary Document.

From the above diagram, we can clearly see how the entries for the Collection and Binary Document in the Collections Table are mirrored to the filesystem. We can also see that the key for linking the Binary Document from the Collections Table to the Filesystem is the database's fully qualified URI of the Binary Document, e.g. /db/mydoc.bin.
A much cleverer man than I once said:
Any problem in computer science can be solved with another level of indirection
- Prof. David Wheeler
My initial design for what we decided to term "Deduplicating BLOB Storage", involved an evolution on Alex's design, whereby I would still store the content of Binary Documents on the filesystem, but rather than referencing them by their location in the database, I would reference them by a UUID (Universally Unique Identifier).
By referencing the documents by UUID I could break the 1-to-1 mapping between the Document object's location and its content, thus adding a level of indirection. In practical terms this would mean naming the BLOB file on the filesystem by a UUID and then storing the UUID with the Document Object in the Collections Table. I envisaged that many Document Objects in the Collections Table could point (by UUID) to the same BLOB file on disk.

Before this UUID based design was attempted, I wanted to ensure that I could be certain that it worked correctly, for that I needed tests. Looking around at the existing handling of Binary Documents I realised that there was a lack of tests for what we currently had. I felt that first we needed to write high-level tests that proved eXist-db's existing handling of Binary Documents, these tests could then later be executed against the new design to guard against any regressions.
Fixing eXist-db's Crash Recovery
To cut a longer story short, we wrote the tests and they showed a number of problems with Binary Documents (and also later with XML Documents) all related to Journalling and Recovery in the case of a system crash.
Diagnosing and fixing these issues was very time consuming, and without getting into the specifics of past problems, it is enough to say that I developed many tests and fixed many more issues related to Journalling and Recovery. If your interested you can see my relevant Pull Requests: #989, #1838, #1871, #2248, #2254, #2266, #2293, #2302, and #2306.
New BLOB Store Design - Round 2, Hash Functions
Whilst the UUID design was promising and works well for copying existing Binary Documents within the database, it by itself is not enough.
Consider the scenario whereby a user stores a new Binary Document into the database, but that Document's content already exists in the database, how should the system know that when creating the new Document requested by the user, the content should not be stored for a second time, but should in-fact reference an existing BLOB file on the filesystem?
Hash Functions! If we know the hash of each BLOB file, then when the user requests to store a new Binary Document, we can compute the hash of the content of their new Binary Document, if it matches the hash of an existing BLOB file, we can simply discard their content and link their new Binary Document to the existing BLOB file.
But wait? Where should we store the hash of the BLOB file? We could store it in each Document Object in the Collections Table, but we then have to store both a UUID and hash value for every Binary Document, which seems wasteful, especially when we know that due to duplicates, many of these UUIDs and hashes will be the same.
The trick is to realise that as we will only store unique BLOB files, the hash of each BLOB file itself will be unique! Therefore, we no longer need the UUID to act as a unique identifier, instead we can just use the hash.

With the Hash based design, when a new Document is Stored, the hash of its binary content is computed. If a BLOB file named by the hash already exists in $DATA_DIR/blob, then we need not store the BLOB file again, instead we can just reference it by its hash from the new Document Object we create in the Collections Table.
Whilst this design improves on the UUID based design, and we can handle both copying existing documents and storing new documents that have the same content as existing documents, there is still one major issue which we have not examined.
When should we delete a BLOB file? When a user requests to delete a Binary Document from the database, we cannot just delete its BLOB file as it may now be referenced by other Binary Document objects in the Collections Table. We can only delete a BLOB file when the last Binary Document which references it is deleted.
On deletion of a Binary Document, performing a complete scan of the Collections Table B-tree to find any further references to its BLOB file, so that we can determine whether the BLOB file should be deleted, would be a very I/O and time expensive operation! Instead, we can maintain a reference count for each BLOB file.
Final New BLOB Store Design - Blob Table
Again, the answer to our problems is indirection! Rather than linking between the Binary Document Objects in the Collections Table and the BLOB files on the filesystem, we now introduce a Blob Table between the two.

The Blob Table is not only responsible for linking the Binary Document to a BLOB file, but also for maintaining both:
- A reference count. The number of Binary Document Objects which reference the BLOB file.
- An active readers count. The number of active readers currently accessing the BLOB file.
Storing a Binary Document
When the user wants to store a new Binary Document, the database looks up the hash of the Binary Document's content in the Blob Table, if an entry exists the reference count is incremented and the new content discarded, if not, a new entry with a reference count of 1 is inserted and the content is copied to the filesystem. The entry for the Binary Document Object in the Collections Table is created in the normal way recoding the hash of the BLOB file.
Retrieving a Binary Document
When the user retrieves a Binary Document, first the Binary Document Object from the Collections Table is retrieved, from here when the user requests the content of the Binary Document, a lease to its BLOB file is issued. The lease provides both the data and a release function to the caller. When the lease is issued the number of active readers for the BLOB file is incremented in the Blob Table, and when the lease is released the number of active readers is decremented. The active readers count ensures that BLOB files are not deleted prematurely.
Removing a Binary Document
When the user wants to remove a Binary Document, first the Binary Document Object from the Collections Table is retrieved, the reference count for the in the Blob Table is then decremented, if the reference count is now zero, then the BLOB file is scheduled for deletion (more about that below). The entry for the Binary Document Object in the Collections Table is then removed in the normal way.
Deleting a BLOB File
BLOB Files are never directly deleted, instead they are scheduled for deletion by adding them to a queue prioritised by the number of active readers. This queue is processed by a separate Vacuum thread which takes a best attempt approach at deleting the BLOB file. The Vacuum thread, first checks that both the BLOB file's reference count and active readers count are zero, if they are then the BLOB file is deleted and its zero'd entry is removed from the Blob Table.
If the Vacuum thread finds that a BLOB file's reference count is greater than zero, then this implies that before the BLOB file could be deleted, another thread has added a new Binary Document which references the same BLOB file. Rather than deleting the BLOB file, we discard the request to delete it, allowing it to continue being reused, we call this process Recycling. Recycling allows for a nice optimisation by reducing disk I/O when frequently removing and adding Binary Documents that have the same content.
If the Vacuum thread finds that a BLOB file's active readers count is non-zero, then it implies that there are still active users and that the BLOB file should not yet be deleted. Instead of deleting the BLOB file, the vacuum thread re-schedules the BLOB file for later attempted deletion.
To ensure the safe recovery of the system in the event of a crash, there are actually a few other conditions which are imposed on when BLOB files can be deleted, but we will cover those another time.
Copying a Binary Document
Finally, I have implemented a logical optimisation for copying Binary Documents. Whilst Copying Binary Documents can be implemented by retrieving the existing Binary Document and then Storing it again, that would also mean recomputing the hash of the Binary Document when we try to store it again. As we already know the hash, when the user wants to copy a Binary Document, the database now simply increments the reference count of the BLOB file associated with the original Binary Document, and then stores a new Binary Document Object in the Collections Table which references the same BLOB file hash.
Summary
This is already a long post, so I won't further cover here either, the technical implementation detail of my new BLOB Store, or how crash recovery of the new BLOB Store works. I will save those topics for future posts/discussion.
The new Deduplicating BLOB Store design I have created for eXist-db allows the database to only store the content of distinct Binary Documents once.
My implementation offers the following benefits:
- Reduced disk storage space.
Duplicate BLOB files are only stored once. - Fast copy of Binary Documents.
Only a new Binary Document Object needs to be created, the content (i.e. the BLOB file) is not copied. - Fast move of Binary Documents.
Only the existing Binary Document Object needs to be re-linked in the Collections Table, the Blob file itself is neither copied or moved. - Fast delete of Binary Documents.
When there are duplicates, the BLOB file is not actually deleted. When there are no duplicates, the BLOB file is deleted asynchronously by a background Vacuum thread. - Increased concurrency.
The implementation provides non-blocking and lock free operations on Binary Documents. - Reduced disk storage space for crash-safe recovery.
Previously, when a Binary Document was deleted, a copy of its BLOB file had to be kept in case of crash-recovery. This copy is no longer needed.
The knowledge gained and new technology created with this implementation leaves us in an excellent position for attempting something similar with XML documents in future. Admittedly, achieving the same functionality and performance gains for XML documents will be more complicated due to how their composite nodes are stored in eXist-db, but I can already see a number of options ;-)
Download
If you wish to try out my new BLOB Store implementation, my changes are available in PR #2314, or you can download pre-built binaries of eXist-db 4.5.0 patched with the new BLOB store at http://static.adamretter.org.uk/blob-dedup/.