Recently on a new project where I needed to transform documents from a variety of source formats into a standard output format, I decided to try and orchestrate this by using XProc 3.0. In the past when faced with a similar challenge I have typically built the pipeline itself in Java or XQuery, but I felt that the goals and purpose of XProc should mean that it is a better fit for such projects.
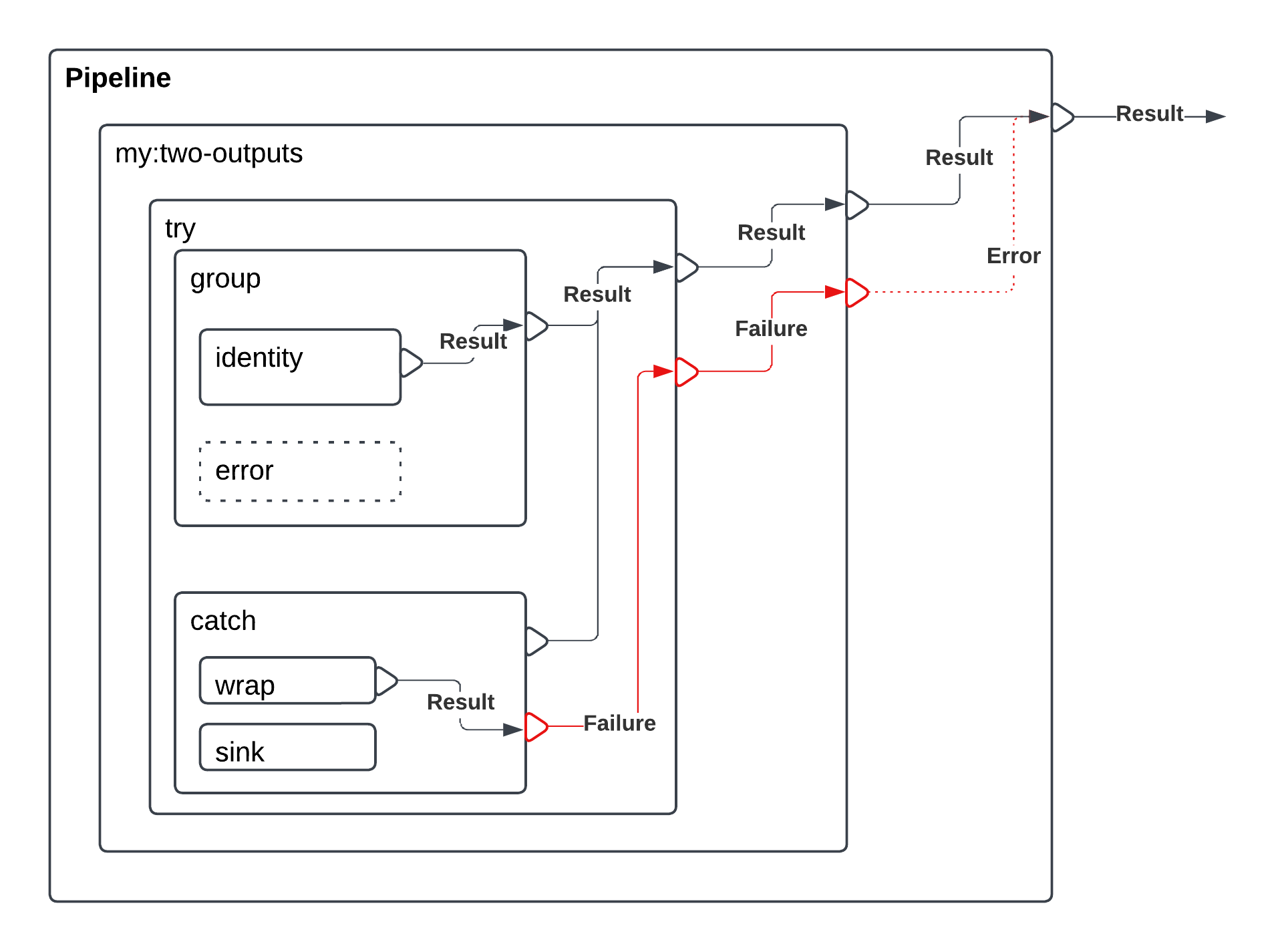
One aspect that I have repeatedly been struggling with when building my XProc 3.0 pipeline is that of comprehending the exact flow of documents and/or data through the pipeline. Specifically, I want to be able to have separate success and failure flows in my pipeline, so that I can manage them with independent steps. To achieve this, I want to be able to capture any failures and route them to separate sub-pipelines that handle or recover from such failures.
I have tried to illustrate below an example of a simple pipeline where the main step of consequence is "Parse Document", whose tasks is to parse an XML document. If the parsing succeeds the pipeline should store the document to a location on the filesystem, and then return a copy of the document as the output of the pipeline. If the parsing fails, perhaps because the document is not well-formed, then it should create an error report of the details and store the error report to a different location on the filesystem.
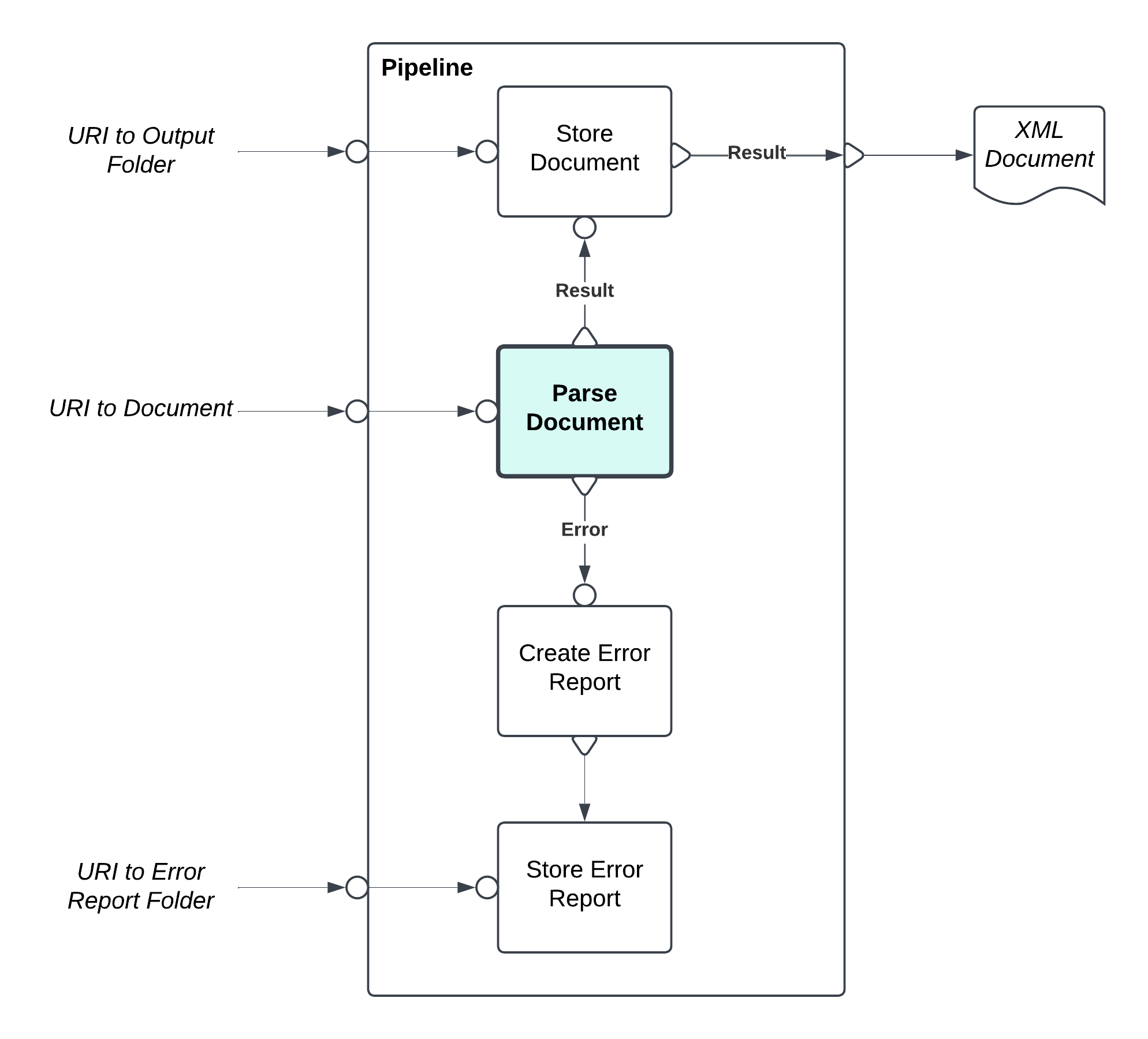
The point I am trying to illustrate is that I would like a different flow through the pipeline depending on whether the "Parse Document" step succeeds or fails.
In XProc 3.0 we can encapsulate any other step within a try/catch step. In this case we could encapsulate a p:load step within a p:try sub-pipeline. This enables us to catch and handle any error that is raised by the p:load step. XProc 3.0 also has the concept of Output Ports, and we can use them in this case to setup two Output Ports, one for success, and a separate one for any failure.
The theory, at least to me, of what we need to do is simple and straight-forward. Unfortunately, I spent a couple of days struggling to get this working in XProc 3.0; I experimented with many syntactic variations to try and implement this. Ultimately, after some kind pointers from both Norman Walsh and Achim Berndzen (thank you both!), I was able to construct an example that finally worked. I am reproducing this below for both my own reference, and for anyone else that might want to achieve the same thing.
Routing from Try/Catch in XProc 3.0
<?xml version="1.0" encoding="UTF-8"?>
<p:declare-step
xmlns:p="http://www.w3.org/ns/xproc"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:my="http://me"
version="3.0">
<!-- TODO(AR) switch which one of these is commented out to see the result or the error -->
<!--
<p:output port="result" sequence="true" primary="true" pipe="result@two-outputs-example"/>
-->
<p:output port="result" sequence="true" primary="true" pipe="error@two-outputs-example"/>
<!-- This step that has two output ports, only one will contain documents.
* 'result' has documents if everything executes successfully.
* 'error' has a document describing any error that occurred.
-->
<p:declare-step type="my:two-outputs-example">
<p:output port="result" sequence="true" primary="true"/>
<p:output port="error" sequence="true" pipe="failure@try1"/>
<p:try name="try1">
<p:output port="result" sequence="true" primary="true"/>
<!-- NOTE(AR) within this group could be a `p:load` or anything else that might raise an error -->
<p:group>
<p:identity>
<p:with-input>
<p:inline><TRY-RESULT>FROM TRY</TRY-RESULT></p:inline>
</p:with-input>
</p:identity>
<!-- TODO(AR) comment out the line below out to instead get the 'result' of the try sub-pipeline -->
<p:error code="ADAM-ERROR-01"/>
</p:group>
<p:catch>
<p:output port="result" sequence="true" primary="true"/>
<p:output port="failure" sequence="true" pipe="result@caught"/>
<p:wrap name="caught">
<p:with-input port="source" pipe="error"/>
<p:with-option name="wrapper" select="xs:QName('my:error-report')"/>
<p:with-option name="match" select="'/'"/>
</p:wrap>
<!-- NOTE(AR) we must discard output from catch sub-pipeline to stop it going to the primary 'result' output port -->
<p:sink/>
</p:catch>
</p:try>
</p:declare-step>
<my:two-outputs-example name="two-outputs-example"/>
</p:declare-step>To experiment with this XProc 3.0 pipeline, you can run it using Morgana XProc IIIse, by executing:
$ ./Morgana.sh example-try-catch-routing.xprocIf you want to run and see the result of the Success flow:
- Uncomment the line:
<p:output port="result" sequence="true" primary="true" pipe="result@two-outputs-example"/> - Comment out the line:
<p:output port="result" sequence="true" primary="true" pipe="error@two-outputs-example"/> - Comment out the line:
<p:error code="ADAM-ERROR-01"/>
If you want to run and see the result of the Failure flow:
- Comment out the line:
<p:output port="result" sequence="true" primary="true" pipe="result@two-outputs-example"/> - Uncomment the line:
<p:output port="result" sequence="true" primary="true" pipe="error@two-outputs-example"/> - Uncomment the line:
<p:error code="ADAM-ERROR-01"/>
I have tried to show an illustration below of the data flow through such a pipeline. I admit that it is not a very good illustration and it might have been a better idea to flatten all of the steps and connect them by their ports only rather than showing them in the same nested fashion as that of the XProc syntax.